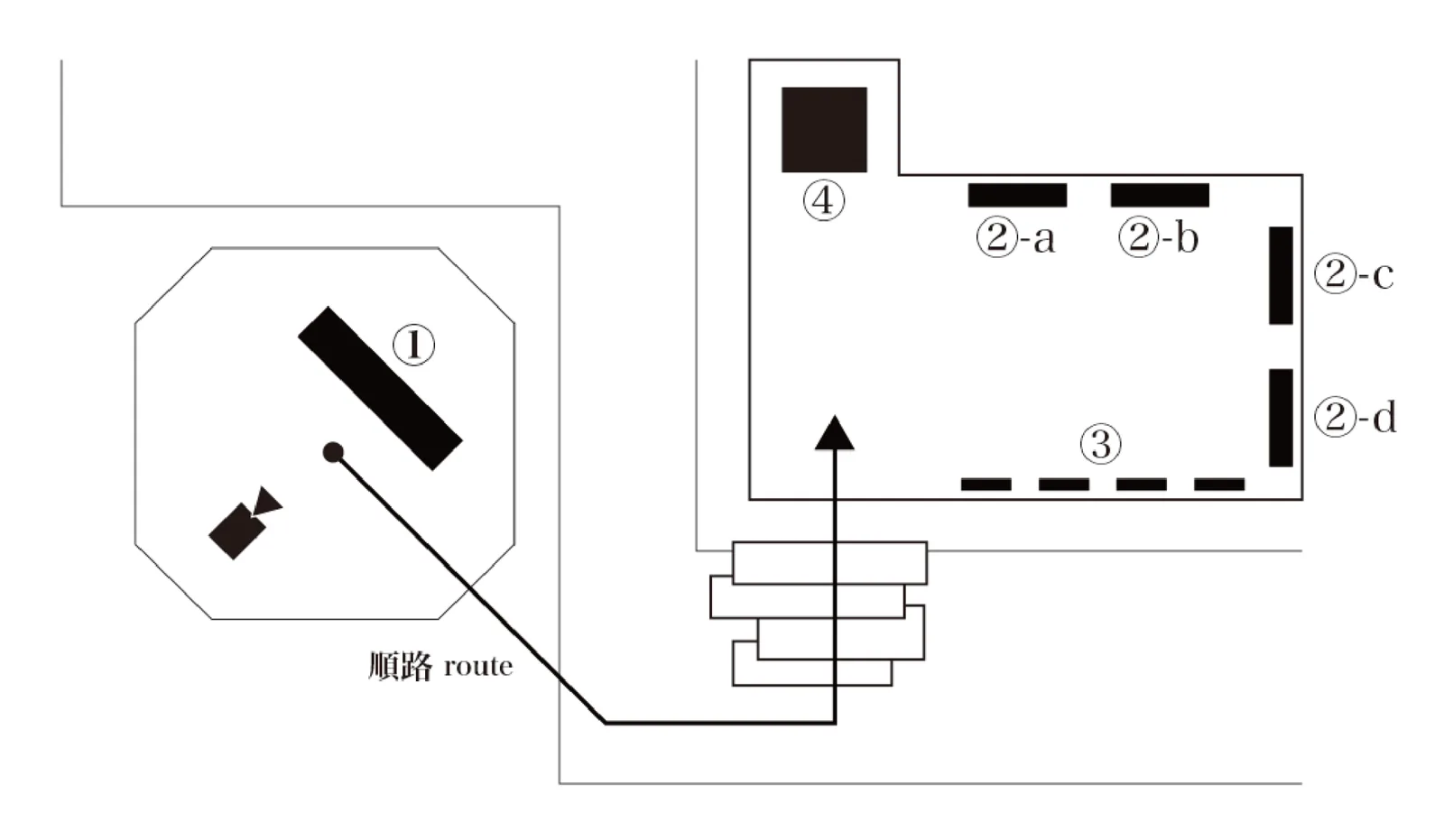
① recursive visual
② Real-Time Training Process
③ Generated Images
④ Beyond Perception Model
"recursive" is a project that explores the theme of "AI's recursive self-learning and the evolution of creativity," developed from the "Beyond Perception Model"—an AI model trained exclusively on approximately 170,000 images independently created by Rhizomatiks—which was presented at "Rhizomatiks Beyond Perception" at KOTARO NUKAGA (Tennoz) under the theme of "AI and Generative Art."
For this exhibition, a large LED display and a camera filming the screen itself were installed at the Omotesando intersection. The LED continuously displays results generated by the AI model, while the AI model recursively learns from its own reflection captured by the camera. This may appear similar to typical interactive video or feedback phenomenon exhibitions, but the actual mechanism is quite different as described below.
Past research has reported that when AI learns from images created by other AI, it negatively affects diversity and quality deteriorates—the risk of collapse rather than evolution has been pointed out.
Reference – Paper on the effects of generative models learning from AI-generated images:
This exhibition attempted to mitigate that risk by incorporating real-world data including the figures of visitors captured by the camera. At the same time, the influence of uncertain factors such as camera and display characteristics and changes in ambient light on AI learning became subjects of observation.
Inside the exhibition hall, visitors can observe what kind of learning process this AI model follows recursively. As mentioned above, if an AI model continues learning from its own image, there is a possibility of collapse. However, in this work, by having people and ambient light intervene in the AI's self-learning loop, model collapse is avoided, aiming for emergent expression beyond mere feedback or machine learning. This exhibition was a challenging attempt to present this entire process as an artwork.
This learning process also holds the potential for visitors captured by the camera to influence it. How does your existence affect AI's creativity? "recursive" is a new artistic experience of co-creation between AI and humans pioneered by Rhizomatiks.
_Exhibition name: Rhizomatiks "recursive"
Duration: September 14 (Sat) – October 3 (Thu), 2024
Hours: 10:00 – 20:00
Venue: OMOTESANDO CROSSING PARK
Cooperation: KOTARO NUKAGA_
Releasing AI in Omotesando: Innocent Contemplation, Recursivity and Contingency
"recursive" is a spin-off and development of "Rhizomatiks Beyond Perception" currently being held at KOTARO NUKAGA (Tennoz). It is an attempt to release AI at the Omotesando intersection, where Tokyo's most refined sensibility information converges. For technology stakeholders in this transitional period, examining the relationship with humans by treating AI as a subjective agent or anthropomorphizing it is a matter of great interest.
Rhizomatiks' attempt to have AI re-learn images it created with the same model (itself) is both radical and enlightening. It is known that self-learning by AI causes deterioration and risks model collapse. In recursive, an LED screen and a camera 5 meters away are installed in the public space of Omotesando. Rhizomatiks is attempting emergent expression beyond mere self-learning by incorporating real-world data that "contingently" intervenes—people, objects, light, and weather changes—between them. It can be seen as both a warning against our current state of being trapped in filter bubbles and prone to self-contradiction, and a proposal for avoiding this.
When the AI model views the generated image A as external information, it simultaneously includes the figures of viewers looking at its own creation A. German contemporary artist Thomas Struth's series photographing museum visitors together with artworks captures the politics and institutionality of museum space as a space for viewing art.
However, for AI models there is no hierarchy of information data, so sunlight reflected on the screen and the figure of a person standing in front of it are processed as information that has contingently intervened equally. Data captured from a zero-degree viewpoint mixes with image A to generate new images.
Humans expand their cognition through dialectical and speculative feedback by layering new experiences on their memories. What is remarkable about this exhibition is the sensitivity and aesthetics of Rhizomatiks' information processing, showing AI that is innocently and defenselessly open to external stimuli, and the process of its capture and generation as training batches.
Square monitors display live images captured by the camera, and generated images are shown next to them. The monitor on the left of the training batch, which shows the process in segments, displays the learning materials from the past hour. The clarity and beauty of this process, where figures of people who happened to pass by are incorporated into the generation process. On the right is the noise error, showing the trial-and-error process as a vibrant noise screen as various pixels entangle while the AI tries to reach a more accurate image goal from the mixture of image A and contingency.
Not just the goal of generated images, but how to show the process. This project, which presents the creative process through recursivity and contingency with its own creations, the viewers looking at them, and surrounding light and other phenomena as data, demonstrates the unknown possibilities brought about by AI's innocent contemplation and meticulous trial and error toward a goal.
Exhibition Description
Visual expression generated by an AI model trained on original materials with the theme of "AI's recursive self-learning and the evolution of creativity" based on the Beyond Perception Model.
In this work as well, users can generate and appreciate original images using this model. Furthermore, experts and engineers can use this model to design new works and services, and the license for this is also granted to the work's owners.
In this area, you can observe AI learning in real-time using a camera through four processes.
Visualizing how AI learns while taking in data through a technique called mini-batch learning. Mini-batch learning is a method where data is divided into small groups (batches) rather than processing large amounts at once. This technique allows efficient computation and reduced memory usage, making it the method adopted in almost all current AI training.
The displayed image groups are the actual mini-batches currently being used by the AI. In addition to the latest images acquired by the camera in real-time learning, images acquired within the past hour are also randomly mixed and used. This allows you to visually track what kind of data the AI is processing as it advances its learning.
This learning uses the Latent Diffusion Model (LDM). The latent diffusion model converts data into an abstract dimension called latent space and generates data while handling noise in that space, making it suitable for efficiently generating high-quality images.
The "noise error" visualized here is the error between the output estimated by the AI during learning and the actual training sample being used. Specifically, the AI adds noise to the original image, maps it to latent space, and tries to gradually remove the noise to reconstruct the original image. In this process, the difference between the estimated output and the training sample is calculated as "error," and by reducing this error, the AI learns to generate images more accurately.
This exhibition visualizes in real-time how much "error" is occurring, allowing observation of how the error decreases as the AI advances its learning.
※Training data captured from the camera (②-a) and visualization of that learning progress (②-b). When observed simultaneously, you can clearly see how AI learns from the real world.
②-c: Images generated by models from past to present
Using the same parameters as the acrylic works exhibited at Tennoz, images generated by the AI model every 100 learning steps are recorded and played back. This video is updated in real-time, allowing observation of how this model changed until it reached its current output.
※Even with the same parameters, the significant changes in output are clearly apparent.
②-d: Camera input video
This is a through-output of images from the outdoor camera, and the images output to this LED are used directly as learning samples.
In the first half of the exhibition, 4 images generated by the Beyond Perception Model are displayed. By printing and displaying images carefully selected by Manabe from 100,000 images generated by changing inputs, the diversity and high quality of the model's output is demonstrated. These images are generated through an approach different from traditional abstract painting or generative art, presenting a unique fusion of texture and pattern.
In the latter half of the exhibition, acrylic panels newly generated using the AI model that grew through the learning process were displayed.
The "Beyond Perception Model," the AI model that forms the basis of this exhibition and is currently on display at KOTARO NUKAGA (Tennoz), is also shown here as a reference exhibition.
This AI model has learned the characteristics and trends of videos produced by Rhizomatiks and can imitate their unique visual language. Specifically, it specializes in understanding and reproducing patterns of color, shape, and composition unique to Rhizomatiks, and can practically infinitely generate new visual expressions by combining these elements. At the same time, this model embodies Rhizomatiks' visual identity and functions as a tool to extend their creative legacy to the digital generation. Users can use this model to generate and appreciate original images. Furthermore, experts and engineers can use this model to design new works and services, and the license for this is also granted to the work's owners.
Beyond Perception Model details: